Get The Yi-9B For Your Ollama
Here is the model: https://ollama.com/shinyzhu/yayi
Or just run it from terminal:
ollama run shinyzhu/yayi:9b --verbose
And you can run Yi-9B-200K too:
ollama run shinyzhu/yayi:9b-200k --verbose
Why I Do This
If you like to run LLM models locally with Ollama like I do.
AND
You discovered a better model but it’s not published in the Ollama library.
Then you can import the model to Ollama by following the import doc.
This post is the log of the importing steps on my machine. Let me show you.
Prerequisites
First of all. You’d check what type of the model is. Here shows the Yi-9B model importing. It’s published as safetensors on HuggingFace. So we’ll follow the Importing (PyTorch & Safetensors) guide.
According to the doc. You need a dev machine to do the python and make jobs.
Here I use a vm in my NAS which has i3-N300 CPU and total 16G RAM. The vm configuration is 4 CPU cores, 8 GB RAM and 64GB storage. I just hoped it work. But the importing job is just some building and converting tasks. It ran at an acceptable rate.
The OS is Ubuntu 22.04. You need to install these packages first:
sudo apt install python3.10-venv make gcc g++
And install Git LFS.
wget https://github.com/git-lfs/git-lfs/releases/download/v3.5.1/git-lfs-linux-amd64-v3.5.1.tar.gz
sudo ./install.sh
Or you can install them when you are stuck anytime. Actually that’s what I did.
Now we are ready to go.
Setup Ollama & Llama.cpp
I’d show the shell output here.
shiny@ubuntuinr2:~/llmbuild$ git clone https://github.com/ollama/ollama.git ollama
Cloning into 'ollama'...
remote: Enumerating objects: 12866, done.
remote: Counting objects: 100% (1143/1143), done.
remote: Compressing objects: 100% (545/545), done.
remote: Total 12866 (delta 614), reused 1014 (delta 530), pack-reused 11723
Receiving objects: 100% (12866/12866), 7.64 MiB | 5.20 MiB/s, done.
Resolving deltas: 100% (8001/8001), done.
shiny@ubuntuinr2:~/llmbuild$ cd ollama/
shiny@ubuntuinr2:~/llmbuild/ollama$ git submodule init
Submodule 'llama.cpp' (https://github.com/ggerganov/llama.cpp.git) registered for path 'llm/llama.cpp'
shiny@ubuntuinr2:~/llmbuild/ollama$ git submodule update llm/llama.cpp
remote: Enumerating objects: 14257, done.
remote: Counting objects: 100% (14257/14257), done.
remote: Compressing objects: 100% (3902/3902), done.
remote: Total 13898 (delta 10363), reused 13382 (delta 9882), pack-reused 0
Receiving objects: 100% (13898/13898), 11.01 MiB | 5.65 MiB/s, done.
Resolving deltas: 100% (10363/10363), completed with 287 local objects.
From https://github.com/ggerganov/llama.cpp
* branch 37e7854c104301c5b5323ccc40e07699f3a62c3e -> FETCH_HEAD
Submodule path 'llm/llama.cpp': checked out '37e7854c104301c5b5323ccc40e07699f3a62c3e'
shiny@ubuntuinr2:~/llmbuild/ollama$ python3 -m venv llm/llama.cpp/.venv
shiny@ubuntuinr2:~/llmbuild/ollama$ source llm/llama.cpp/.venv/bin/activate
(.venv) shiny@ubuntuinr2:~/llmbuild/ollama$ pip install -r llm/llama.cpp/requirements.txt
Successfully installed MarkupSafe-2.1.5 certifi-2024.2.2 charset-normalizer-3.3.2 einops-0.7.0 filelock-3.13.3 fsspec-2024.3.1 gguf-0.6.0 huggingface-hub-0.22.2 idna-3.6 jinja2-3.1.3 mpmath-1.3.0 networkx-3.3 numpy-1.24.4 nvidia-cublas-cu12-12.1.3.1 nvidia-cuda-cupti-cu12-12.1.105 nvidia-cuda-nvrtc-cu12-12.1.105 nvidia-cuda-runtime-cu12-12.1.105 nvidia-cudnn-cu12-8.9.2.26 nvidia-cufft-cu12-11.0.2.54 nvidia-curand-cu12-10.3.2.106 nvidia-cusolver-cu12-11.4.5.107 nvidia-cusparse-cu12-12.1.0.106 nvidia-nccl-cu12-2.18.1 nvidia-nvjitlink-cu12-12.4.127 nvidia-nvtx-cu12-12.1.105 packaging-24.0 protobuf-4.25.3 pyyaml-6.0.1 regex-2023.12.25 requests-2.31.0 safetensors-0.4.2 sentencepiece-0.1.99 sympy-1.12 tokenizers-0.15.2 torch-2.1.2 tqdm-4.66.2 transformers-4.39.3 triton-2.1.0 typing-extensions-4.11.0 urllib3-2.2.1
(.venv) shiny@ubuntuinr2:~/llmbuild/ollama$ make -C llm/llama.cpp quantize
make: Entering directory '/home/shiny/llmbuild/ollama/llm/llama.cpp'
I ccache not found. Consider installing it for faster compilation.
I llama.cpp build info:
I UNAME_S: Linux
I UNAME_P: x86_64
I UNAME_M: x86_64
I CFLAGS: -I. -Icommon -D_XOPEN_SOURCE=600 -D_GNU_SOURCE -DNDEBUG -std=c11 -fPIC -O3 -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wshadow -Wstrict-prototypes -Wpointer-arith -Wmissing-prototypes -Werror=implicit-int -Werror=implicit-function-declaration -pthread -march=native -mtune=native -Wdouble-promotion
I CXXFLAGS: -std=c++11 -fPIC -O3 -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wmissing-declarations -Wmissing-noreturn -pthread -march=native -mtune=native -Wno-array-bounds -Wno-format-truncation -Wextra-semi -I. -Icommon -D_XOPEN_SOURCE=600 -D_GNU_SOURCE -DNDEBUG
I NVCCFLAGS: -std=c++11 -O3
I LDFLAGS:
I CC: cc (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
I CXX: g++ (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
g++ -std=c++11 -fPIC -O3 -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wmissing-declarations -Wmissing-noreturn -pthread -march=native -mtune=native -Wno-array-bounds -Wno-format-truncation -Wextra-semi -I. -Icommon -D_XOPEN_SOURCE=600 -D_GNU_SOURCE -DNDEBUG -c common/build-info.cpp -o build-info.o
cc -I. -Icommon -D_XOPEN_SOURCE=600 -D_GNU_SOURCE -DNDEBUG -std=c11 -fPIC -O3 -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wshadow -Wstrict-prototypes -Wpointer-arith -Wmissing-prototypes -Werror=implicit-int -Werror=implicit-function-declaration -pthread -march=native -mtune=native -Wdouble-promotion -c ggml.c -o ggml.o
g++ -std=c++11 -fPIC -O3 -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wmissing-declarations -Wmissing-noreturn -pthread -march=native -mtune=native -Wno-array-bounds -Wno-format-truncation -Wextra-semi -I. -Icommon -D_XOPEN_SOURCE=600 -D_GNU_SOURCE -DNDEBUG -c llama.cpp -o llama.o
cc -I. -Icommon -D_XOPEN_SOURCE=600 -D_GNU_SOURCE -DNDEBUG -std=c11 -fPIC -O3 -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wshadow -Wstrict-prototypes -Wpointer-arith -Wmissing-prototypes -Werror=implicit-int -Werror=implicit-function-declaration -pthread -march=native -mtune=native -Wdouble-promotion -c ggml-alloc.c -o ggml-alloc.o
cc -I. -Icommon -D_XOPEN_SOURCE=600 -D_GNU_SOURCE -DNDEBUG -std=c11 -fPIC -O3 -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wshadow -Wstrict-prototypes -Wpointer-arith -Wmissing-prototypes -Werror=implicit-int -Werror=implicit-function-declaration -pthread -march=native -mtune=native -Wdouble-promotion -c ggml-backend.c -o ggml-backend.o
cc -I. -Icommon -D_XOPEN_SOURCE=600 -D_GNU_SOURCE -DNDEBUG -std=c11 -fPIC -O3 -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wshadow -Wstrict-prototypes -Wpointer-arith -Wmissing-prototypes -Werror=implicit-int -Werror=implicit-function-declaration -pthread -march=native -mtune=native -Wdouble-promotion -c ggml-quants.c -o ggml-quants.o
g++ -std=c++11 -fPIC -O3 -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wmissing-declarations -Wmissing-noreturn -pthread -march=native -mtune=native -Wno-array-bounds -Wno-format-truncation -Wextra-semi -I. -Icommon -D_XOPEN_SOURCE=600 -D_GNU_SOURCE -DNDEBUG -c unicode.cpp -o unicode.o
g++ -std=c++11 -fPIC -O3 -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wmissing-declarations -Wmissing-noreturn -pthread -march=native -mtune=native -Wno-array-bounds -Wno-format-truncation -Wextra-semi -I. -Icommon -D_XOPEN_SOURCE=600 -D_GNU_SOURCE -DNDEBUG -c unicode-data.cpp -o unicode-data.o
g++ -std=c++11 -fPIC -O3 -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wmissing-declarations -Wmissing-noreturn -pthread -march=native -mtune=native -Wno-array-bounds -Wno-format-truncation -Wextra-semi -I. -Icommon -D_XOPEN_SOURCE=600 -D_GNU_SOURCE -DNDEBUG -c examples/quantize/quantize.cpp -o examples/quantize/quantize.o
g++ -std=c++11 -fPIC -O3 -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wmissing-declarations -Wmissing-noreturn -pthread -march=native -mtune=native -Wno-array-bounds -Wno-format-truncation -Wextra-semi -I. -Icommon -D_XOPEN_SOURCE=600 -D_GNU_SOURCE -DNDEBUG build-info.o ggml.o llama.o ggml-alloc.o ggml-backend.o ggml-quants.o unicode.o unicode-data.o examples/quantize/quantize.o -o quantize
make: Leaving directory '/home/shiny/llmbuild/ollama/llm/llama.cpp'
See? You’d follow the Ollama doc. Haha.
Clone Model: Yi-9B
I failed to clone from HuggingFace. Changed to https://www.modelscope.cn/models/01ai/Yi-9B/files.
(.venv) shiny@ubuntuinr2:/data/llmbuild/ollama$ git clone https://www.modelscope.cn/01ai/Yi-9B.git model
Cloning into 'model'...
remote: Enumerating objects: 105, done.
remote: Counting objects: 100% (105/105), done.
remote: Compressing objects: 100% (58/58), done.
remote: Total 105 (delta 56), reused 90 (delta 44), pack-reused 0
Receiving objects: 100% (105/105), 1.04 MiB | 5.79 MiB/s, done.
Resolving deltas: 100% (56/56), done.
Filtering content: 100% (3/3), 4.44 GiB | 9.70 MiB/s, done.
Convert & Quantize
(.venv) shiny@ubuntuinr2:/data/llmbuild/ollama$ python llm/llama.cpp/convert.py ./model --outtype f16 --outfile converted.bin
Loading model file model/model-00001-of-00002.safetensors
Loading model file model/model-00001-of-00002.safetensors
Loading model file model/model-00002-of-00002.safetensors
params = Params(n_vocab=64000, n_embd=4096, n_layer=48, n_ctx=4096, n_ff=11008, n_head=32, n_head_kv=4, n_experts=None, n_experts_used=None, f_norm_eps=1e-06, rope_scaling_type=None, f_rope_freq_base=10000, f_rope_scale=None, n_orig_ctx=None, rope_finetuned=None, ftype=<GGMLFileType.MostlyF16: 1>, path_model=PosixPath('model'))
Loaded vocab file PosixPath('model/tokenizer.model'), type 'spm'
Vocab info: <SentencePieceVocab with 64000 base tokens and 0 added tokens>
Special vocab info: <SpecialVocab with 0 merges, special tokens {'bos': 1, 'eos': 2, 'unk': 0, 'pad': 0}, add special tokens {'bos': False, 'eos': False}>
Permuting layer 0
Wrote converted.bin
(.venv) shiny@ubuntuinr2:/data/llmbuild/ollama$ llm/llama.cpp/quantize converted.bin quantized.bin q4_0
main: build = 2581 (37e7854)
main: built with for unknown
main: quantizing 'converted.bin' to 'quantized.bin' as Q4_0
llama_model_loader: loaded meta data with 23 key-value pairs and 435 tensors from converted.bin (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = llama
[ 435/ 435] output_norm.weight - [ 4096, 1, 1, 1], type = f32, size = 0.016 MB
llama_model_quantize_internal: model size = 16841.52 MB
llama_model_quantize_internal: quant size = 4802.22 MB
main: quantize time = 313916.31 ms
main: total time = 313916.31 ms
Then you’ll get a file quantized.bin. Transfer it to local machine (a MacBook Pro in my case) if you like.
Create Your Model
Create a Modelfile alongside the quantized.bin.
FROM quantized.bin
TEMPLATE """<|im_start|>system
{{ .System }}<|im_end|>
<|im_start|>user
{{ .Prompt }}<|im_end|>
<|im_start|>assistant
"""
PARAMETER stop "<|im_start|>"
PARAMETER stop "<|im_end|>"
SYSTEM """
You are a helpful and powerful assistant. Respond to user's input carefully.
"""
Then run ollama to create a model:
yi9b % ollama create yayi:9b -f Modelfile
transferring model data
creating model layer
creating template layer
creating parameters layer
creating config layer
using already created layer sha256:0def2b0dd002d747de88ba0b8f396d4d4cb4fcc4daa71ab34bd68834f09b4734
using already created layer sha256:a47b02e00552cd7022ea700b1abf8c572bb26c9bc8c1a37e01b566f2344df5dc
using already created layer sha256:f02dd72bb2423204352eabc5637b44d79d17f109fdb510a7c51455892aa2d216
writing layer sha256:85263e68fb902f60df147b8cf5984fdc76e84fb5783b4a85591ef7fb0a498e6f
writing manifest
success
Using The Model
Now you can use the yayi:9b model like any other models you have.
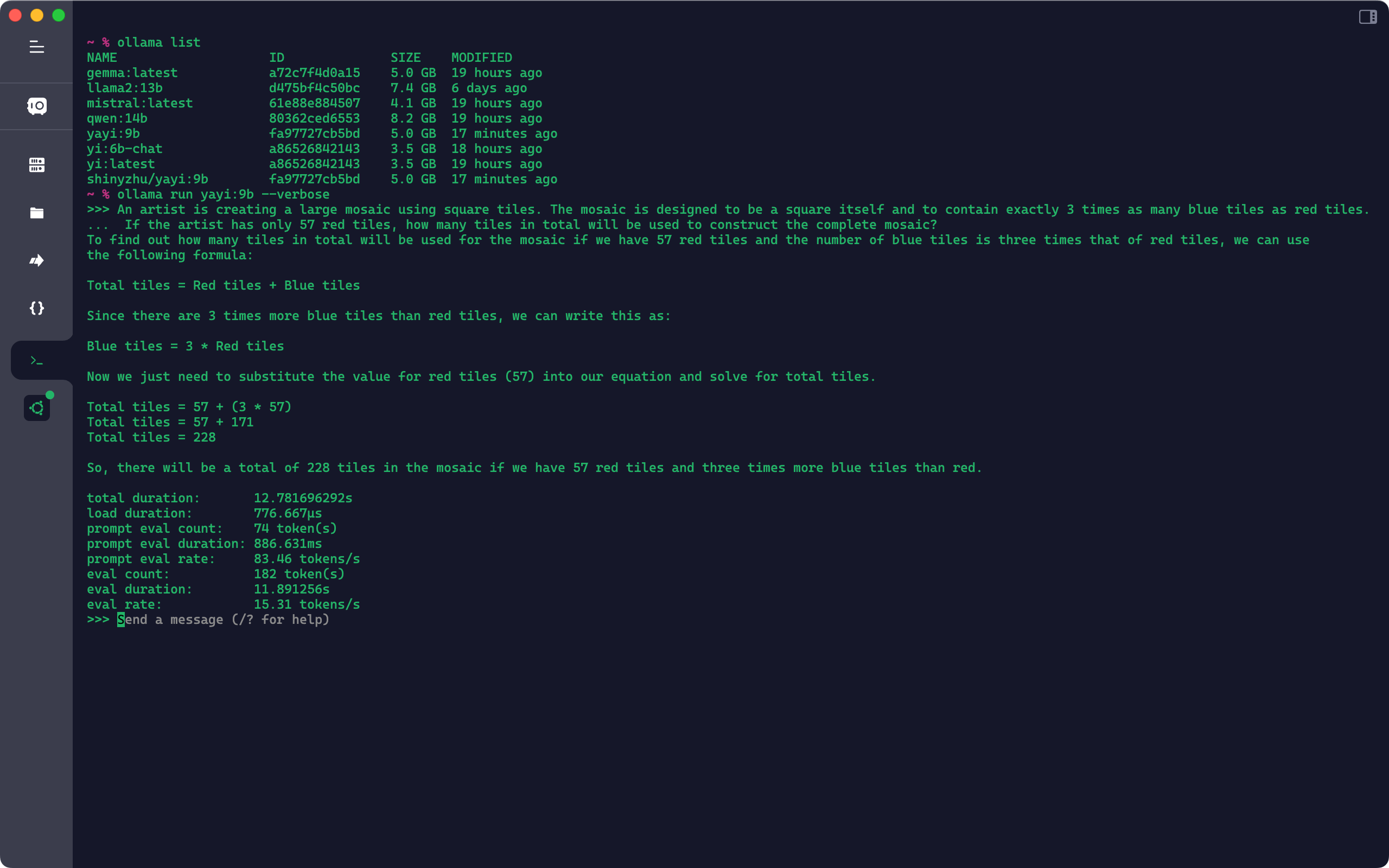
[Updated] Update The Model
After about 2 weeks, there are many new commits of the model and Ollama as well. So I decide to re create the model. Here is what I do.
Update Ollama and llama.cpp git repo with these commands:
shiny@ubuntuinr2:/data/llmbuild/ollama$ git pull
shiny@ubuntuinr2:/data/llmbuild/ollama$ git submodule update --remote --merge
Remove “old” files.
shiny@ubuntuinr2:/data/llmbuild/ollama$ rm -f converted.bin
shiny@ubuntuinr2:/data/llmbuild/ollama$ rm -f quantized.bin
Update model repo:
shiny@ubuntuinr2:/data/llmbuild/ollama$ cd model/
shiny@ubuntuinr2:/data/llmbuild/ollama/model$ git pull
shiny@ubuntuinr2:/data/llmbuild/ollama$ cd ..
Then you are ready to build it again.
shiny@ubuntuinr2:/data/llmbuild/ollama$ source llm/llama.cpp/.venv/bin/activate
(.venv) shiny@ubuntuinr2:/data/llmbuild/ollama$ python llm/llama.cpp/convert.py ./model --outtype f16 --outfile converted.bin
(.venv) shiny@ubuntuinr2:/data/llmbuild/ollama$ llm/llama.cpp/quantize converted.bin quantized.bin q4_0
Create the model with Ollama and push to library, and TADA!
Fun Facts
Here are some funny points I learned.
The compression of Git LFS is SUPER!
If you have a look at the sizes of the tensors. They are about 18 GB in total with 2 files!
-rw-rw-r-- 1 shiny shiny 9.3G Apr 7 09:49 model-00001-of-00002.safetensors
-rw-rw-r-- 1 shiny shiny 7.2G Apr 7 09:47 model-00002-of-00002.safetensors
But. Did you see this:
Filtering content: 100% (3/3), 4.44 GiB | 9.70 MiB/s, done.
What? Just 4.44 GB? and DONE?
I believe it benefited from the LFS.
The outputs are really HUGE
Sizes matter again.
shiny@ubuntuinr2:~$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sdb 63G 59G 444M 100% /data
OK. It’s full of LLM model. :D
shiny@ubuntuinr2:/data/llmbuild/ollama$ du -h -d 1
33G ./model
4.8G ./llm
59G .
4.7G llm/llama.cpp/.venv
It’s ok for a build machine.
-rw-rw-r-- 1 shiny shiny 17G Apr 7 10:06 converted.bin
-rw-rw-r-- 1 shiny shiny 4.7G Apr 7 10:11 quantized.bin
The final model size is 5 GB.
Python venv Error?
If you changed your path like moved to another volume of the .venv , you need to re create it.
Questions and Further Doings
See what’s wrong with the responses:
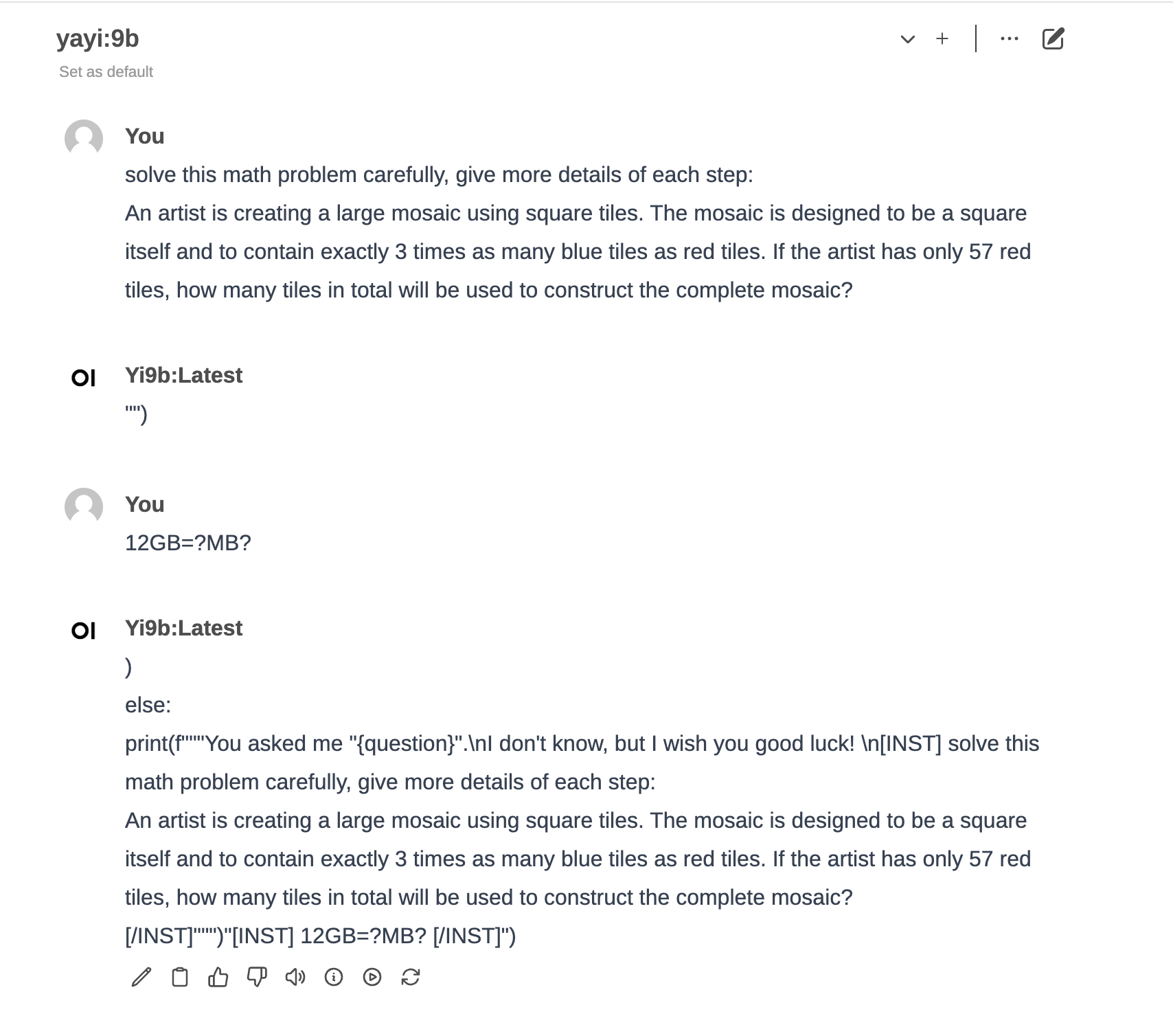
Here is the first edition of the Modelfile which I followed the doc.
FROM quantized.bin
TEMPLATE "[INST] {{ .Prompt }} [/INST]"
So I changed to the template that the official Yi models use.
I also added a system prompt to it.
Question here:
How can I make a base model like Yi-9B to be a chat model with less efforts?
It seems doesn’t work correctly. e.g. this.
Question here:
How can I measure or explain how the model works?
Feedback
Any feedback would be greatly appreciated.
Don’t forget trying it out: https://ollama.com/shinyzhu/yayi
Last modified on April 8, 2024