腾讯问卷
腾讯问卷是我用过最好的问卷系统,没有之一。首先它完全免费,而且没有广告,这个吸引力足够秒杀竞争对手产品了。其次编辑能力很强,设计问卷很容易上手,比如本次的主题附件上传,都能很容易搞定。第三是多平台兼容,微信转发电脑填写都是妥妥的毫无压力。强烈推荐还没有体验的赶快使用起来。
另外还有个微信小程序叫“腾讯投票”,直接微信搜索即可。这个也非常赞,如果你只需要大家投票表决,用小程序就好了,直接在微信里完成编辑分享和统计,统计展示还是实时更新的。
问卷的数据整理
问卷填写后需要对数据进行整理,用来分析调研结果。
因为同学会的缘故,设计了一个收集同学联系方式的问卷,大家都20年没有见了,所以要求大家上传自拍照一张。
腾讯问卷的后台分析非常完善。各项指标一目了然。
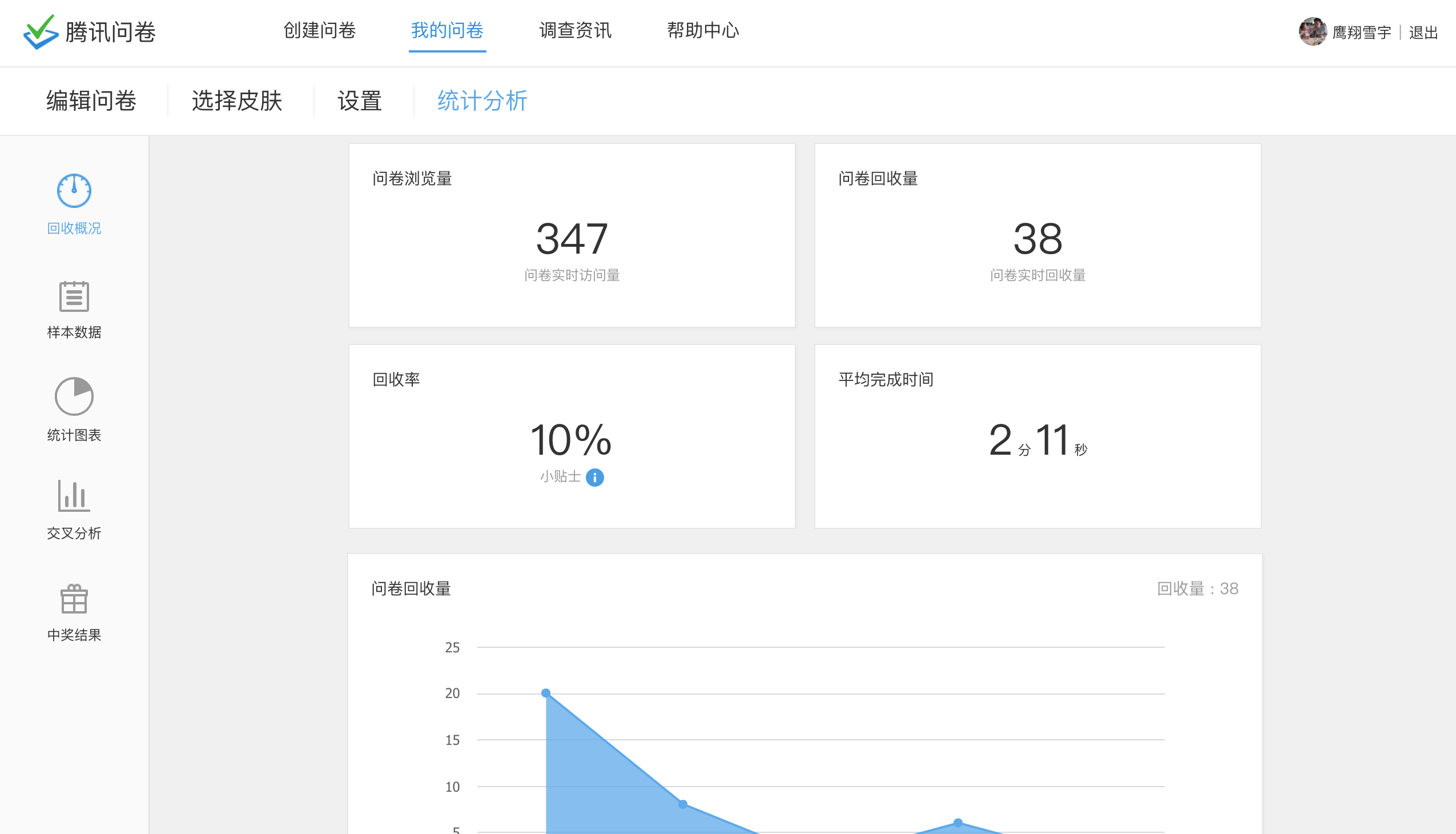
原始数据在“样本数据”一页可以完全下载,格式为csv。这个数据里不包含上传的附件,只包含一个Excel的Hyperlink函数指向服务器上附件地址。但上传的附件只保存30天,所以需要及时下载下来。下载附件在“统计图表”里找到“导出所有文件”即可把文件下载回来。
下载的附件的文件名是随机生成的,样本数据比较多的情况下,完全无法跟csv数据对应。碰到这个问题,我这里就写了一个脚本来自动把附件按照csv数据重命名,这样就一清二楚了。
文件匹配Python脚本
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@author: shinyzhu
"""
import os
import re
import csv
def populate_filename_from_hyperlink(hyperlink):
'''
Populate filename from wj hyperlink in csv
=Hyperlink(""https://wj.qq.com/sfile/survey/answer_file_show?survey_id=1504537&question_id=q-4-PMz4&file_name=0_598e735b686afphpQYku2Ce340.JPG&download=1"",""0_598e735b686afphpQYku2Ce340.JPG"")
'''
match = re.search(r'"(\S+)","(\S+)"', hyperlink) # test re at http://regexr.com
if match:
filename = match.group(2)
return filename
def load_photo_name_data(csv_file, photo_index = 0, name_index = 0):
''' Load wj csv data with specified photo(as key) and name(as value) index to populate data '''
if not os.path.exists(csv_file):
print("The csv file [{}] is not exists.".format(csv_file))
return False
photo_name_data = dict()
with open(csv_file) as data_file:
reader = csv.reader(data_file, delimiter = ',', quotechar = '"')
reader.next() # skip the header
for row in reader:
k = populate_filename_from_hyperlink(row[photo_index])
photo_name_data[k] = row[name_index]
return photo_name_data
def find_rename_photos(photos_dir, photo_name_data):
''' Find photos local and rename them with names data '''
if not os.path.exists(photos_dir):
print("The photos dir [{}] is not exists.".format(photos_dir))
return False
for k in photo_name_data:
parts = k.split('.')
photo_file = os.path.join(photos_dir, k)
new_file = os.path.join(photos_dir, photo_name_data[k] + '.' + parts[1])
print k, ' => ', new_file
if os.path.exists(photo_file):
os.rename(photo_file, new_file)
else:
print photo_file, ' is NOT exist so skipped. <=', photo_name_data[k]
def rename_photos(csv_file, photo_index, name_index, photos_dir):
''' Roll it all '''
photo_name_data = load_photo_name_data(csv_file, photo_index, name_index)
find_rename_photos(photos_dir, photo_name_data)
def main():
rename_photos('1504537_seg_1.csv', 9, 4, 'q-4-PMz4')
if __name__ == '__main__':
main()
逻辑比较清楚。
首先从csv里把附件一列和要匹配的名字一列找出来,在函数load_photo_name_data里实现,参数为csv文件路径,照片列的索引(从0开始,用Excel打开来数)和名字索引。
然后在照片文件夹里根据文件名找文件,依次重命名。在函数find_rename_photos里实现,参数为照片文件夹路径和第一步里的照片名字数据。
最后在main里指定一下你的参数,然后用python运行就好了。
Last modified on October 31, 2023